Cornell EAS Data Lake Setup Tutorial
Welcome to the Cornell University Earth & Atmospheric Sciences Public Data Lake Setup Tutorial! The EAS Data Lake is stored as partitioned ORC files in Amazon S3 and can easily be queried using standard tools like Amazon Athena or Apache Spark. This guide will outline the steps to quickly begin querying the EAS Data Lake with Amazon Athena.
Create the Cornell EAS Data Lake AWS CloudFormation Stack
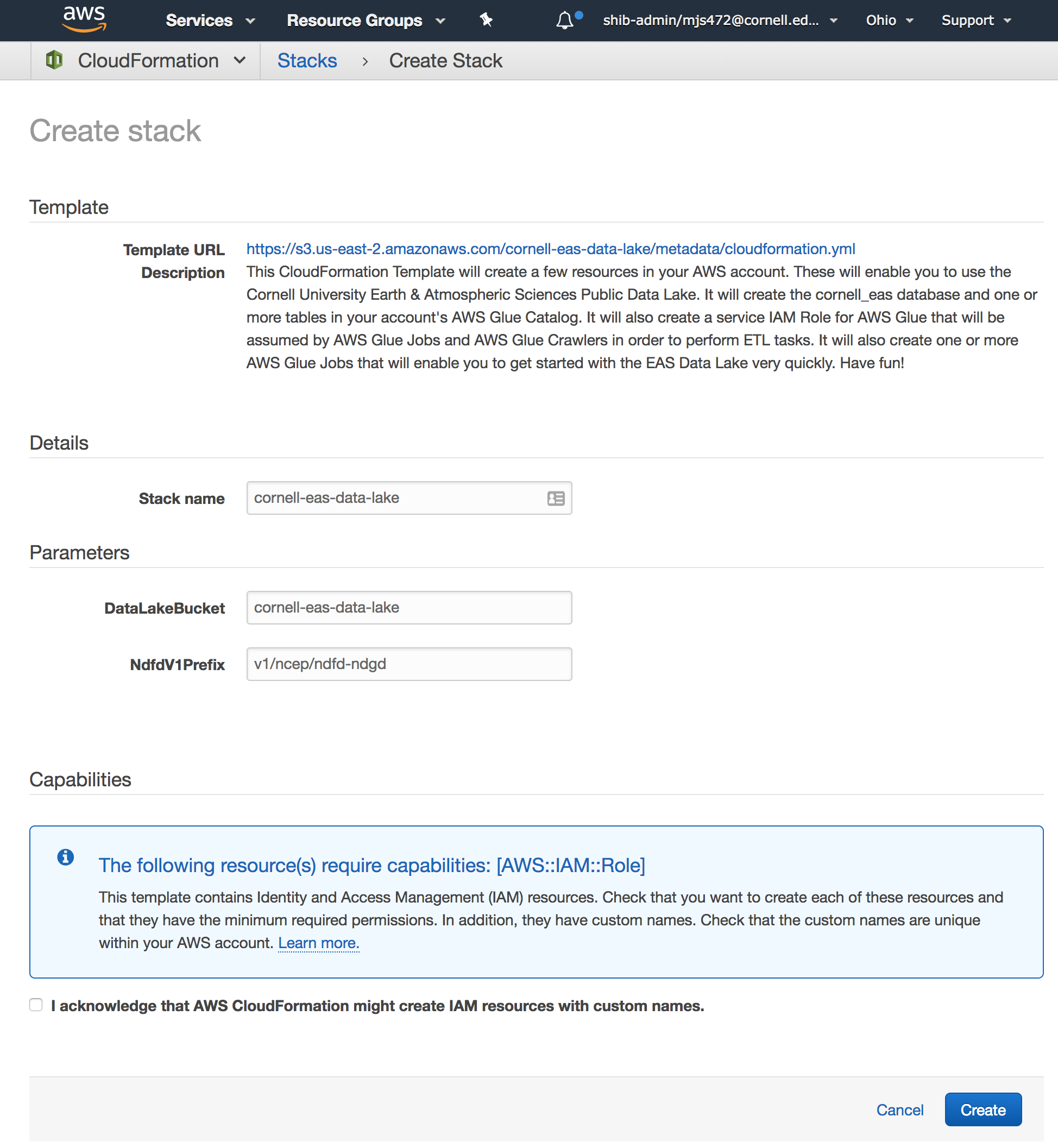
Log into your AWS console, click here and follow the steps below to create the Cornell Earth & Atmospheric Sciences Data Lake in your account. There will be no charge for creating these resources.
When you click the above link you will be taken to the AWS CloudFormation Console as seen in the following screenshot. Read the template description on this page to understand what will be created in your account. No changes are needed in the template inputs but you will need to check the box that states "I acknowledge that AWS CloudFormation might create IAM resources with custom names." Click "Create" to allow the CloudFormation Stack to run. Within a few moments, all of the base resources will be created!
Inspect the AWS Glue Catalog
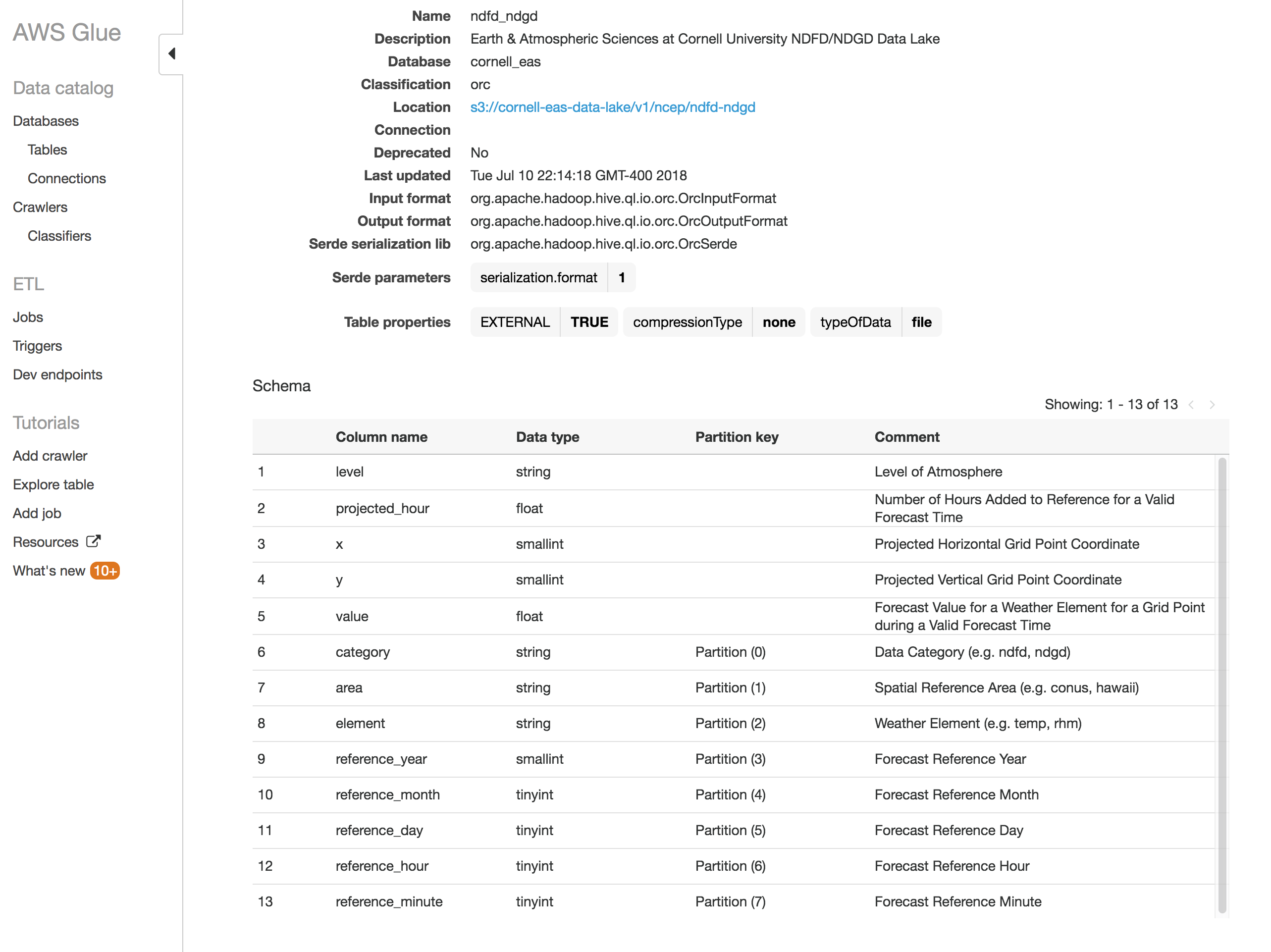
Once the cornell-eas-data-lake Stack has reached the status of "CREATE_COMPLETE," navigate to the AWS Glue Console. You should see a Table in your AWS Glue Catalog named "ndfd_ndgd" that is part of the "cornell_eas" database. You can click on the table to see information about its schema, as seen in the following screenshot. Familiarize yourself with the columns in the table, these will be very useful for the queries you will be able to run shortly!
This table represents historical forecast data that has been converted to ORC format from public archives of the National Digital Forecast Database (NDFD). The NDFD is a 2.5km resolution forecast grid of the Contiguous United States (CONUS) that is created and maintained by the US National Weather Service. The National Digital Guidance Database (NDGD) is a companion dataset that contains the Real-Time Mesoscale Analysis (RTMA) observations that match the NDFD grids. More information about the NDFD/NDGD/RTMA can be found on the NDFD website.
Create the Table Partition Index
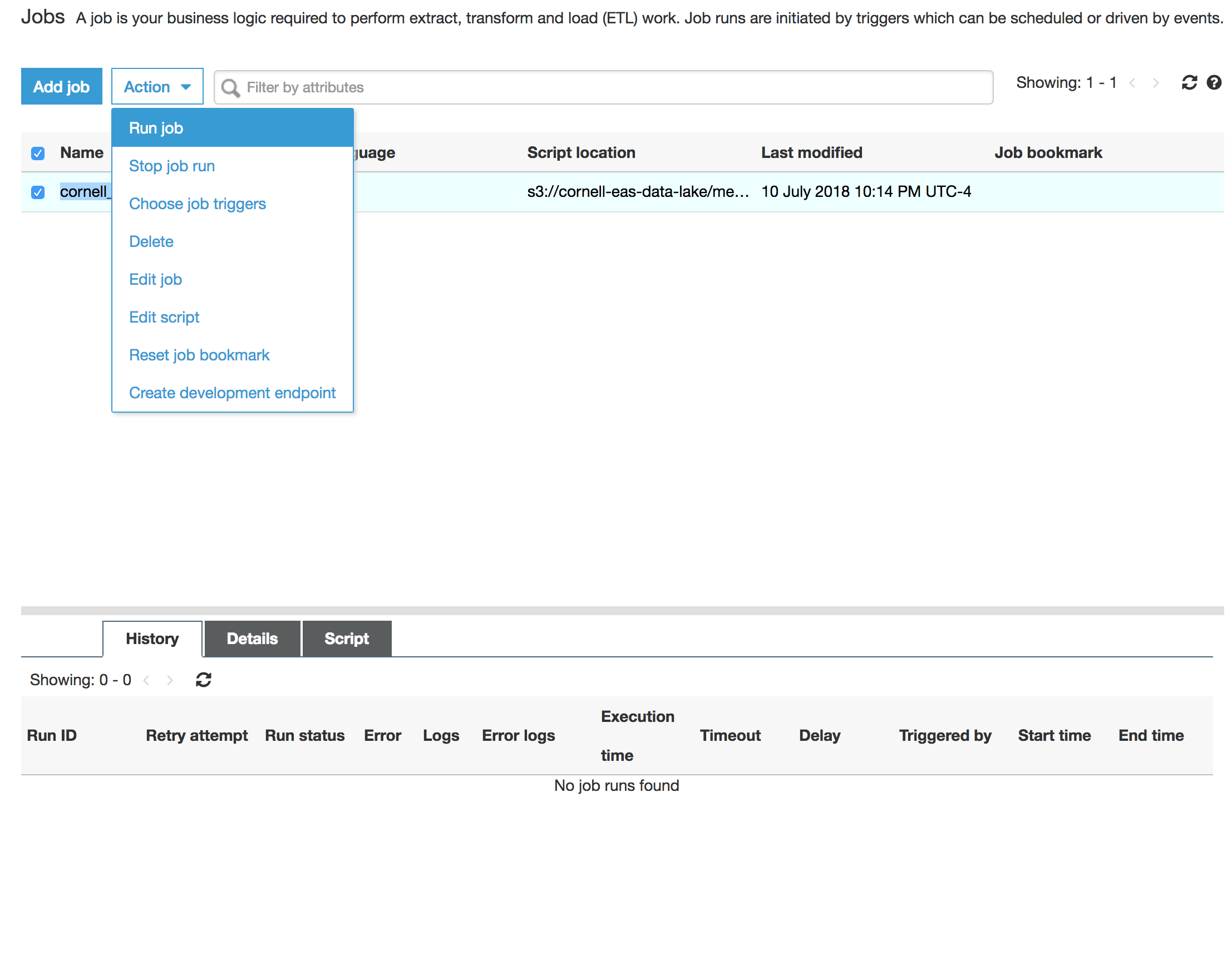
There is one more step needed before you can query this table with Athena. The data is partitioned using a prefix / directory structure in Amazon S3. The data cannot be queried until an index of these partitions is created. Navigate to the AWS Glue Jobs Console, where we have created a Job to create this partition index at the click of a button!
Once in the Glue Jobs Console, you should see a Job named "cornell_eas_load_ndfd_ndgd_partitions." Select this Job, click the "Action" dropdown and choose "Run job" to start the process of loading the partition index. You will see a popup dialog that has some optional parameters to configure. There is no need to change anything, simply run the job.
This Job will take several minutes to run but this is the last preparation step. You can monitor the job's progress in the "History" section of the console when you have the job selected. You can also view the logs here too.
Preview the Table and Begin Querying with Athena
Now that the EAS Data Lake Tables and Partition Indexes are created, you are ready to begin querying the data with Amazon Athena!
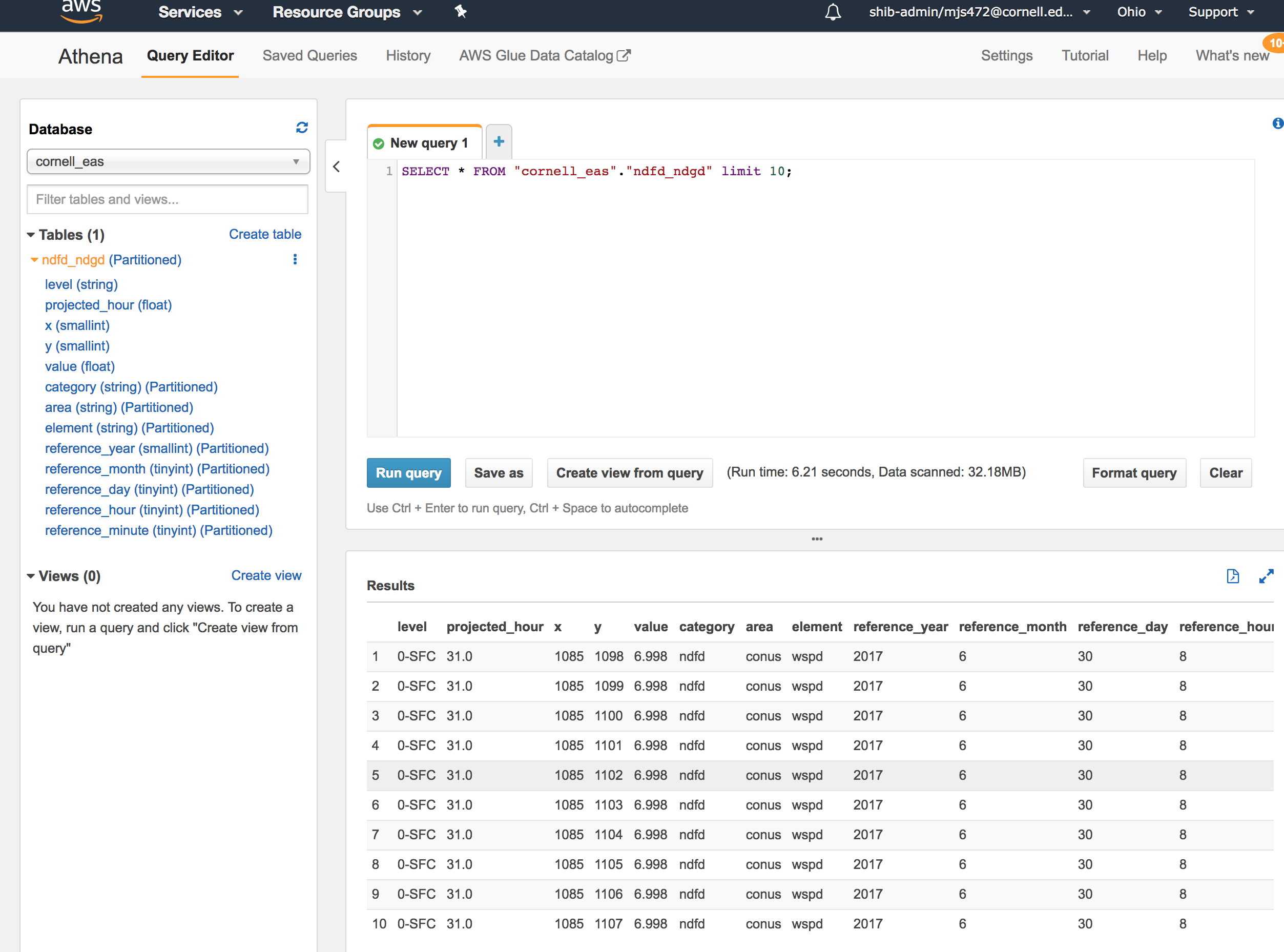
First, navigate to the Athena console. Ensure that the "cornell_eas" Database is selected in the Database dropdown menu. You should then see the "ndfd_ndgd" Table from your AWS Glue Catalog on the screen. Click the three vertical dots next to the ndfd_ndgd Table and choose "Preview Table" from the pop-up menu. You should see a result similar to the following screenshot within a few seconds.
Congratulations! You have confirmed that you can query the Cornell EAS Data Lake from your own AWS Account! Check out our Athena Query Generator Page for help with projecting coordinates to the NDFD grid and constructing more complex queries.